

수업의 진행순서
각각의 자료(총알, 레고, 나뭇조각)에 대해
- 자료정리(name, prep_name 등)
- Sourcing
- Proxy Simulation
- High Detail ↔ Proxy 변환
복합 시뮬레이션 - 총알 (난이도 : 하)
Proxy 버전의 총알을 불러온다.


하드 디테일의 총알도 불러와준다.


RBD Packed Object를 사용하기 위해서는 두 오브젝트 모두 packing을 해줘야한다.
현재 초반의 세팅부분부터 마지막 치환과정을 고려할 필요가 있다. 그렇기 때문에 packing을 하되, 방식을 살짝 바꿔줄 필요가 있다.
Pack 노드에서 바꾸고 싶은 부분이 있다. 바로 'Pivot Location'이다.

Pivot Location : 오브젝트가 Dop Network에 들어가서 계산이 될 때 어디를 중심에 두고 회전과 움직임을 기록할 것인가 이때 쓰일 중심이 바로 Pivot이다.
현재까지는 Centroid, 물체의 바운딩박스 중심을 pivot으로 하였으나, 오늘의 작업에서는 pivot을 origin(원점)에 두도록 한다.

Pivot의 위치로 Origin을 사용하는 이유
우리가 아무리 비슷한 형태로 오브젝트들을 만들어줬다 하여도 바운딩 박스를 기준으로 중심을 찾으면 오브젝트들의 중심이 서로 다를 수 있다. 이 중심이 서로 다른 오차가 크면 클수록, proxy 데이터에서 hard 데이터로 치환하게 될 경우 물체가 이상하게 움직이는것처럼 보일 수 있다. 그래서 오브젝트들의 pivot을 동일한 곳에 두는 것이다.
Proxy / Hard 버전의 총알의 Pivot이 Centroid일 경우,

Proxy / Hard 버전의 총알의 Pivot이 Origin일 경우,

Proxy / Hard 의 Centroid Pivot의 위치의 오차가 매우 작은 편이지만, 그럼에도 미세한 찝찝함마저 날려버릴 수 있도록 Origin을 사용해서 pivot을 일치시켜주도록 하자.
이렇게 해서 회전 중심이 달라서 생길 수 있는 문제는 잡아줬다.
이번에는 두 버전의 총알이 치환되기 쉽도록 이름을 정해주자.
보통 이름을 정해준다고 하면, s@name을 달아준다고 생각하면 된다.
공부하는 동안에는 좀 더 deep하게 이름을 정해주자.
- Dop network 밖에서는 이름으로 s@prep_name / s@ori_name 등으로 지어주자.
이름 지정에 공을 들이는 이유
rigid body 시뮬레이션에서 dop network가 물체를 구분하는 방식이 몇가지가 있다. 그 중에서 가장 대표적인 것이 이름(@name)으로 구분하는 방식이다.
이름이 다르다면 Dop network는 '서로 다른 물체구나' 라고 인지할 것이고, 만약 이름이 같다면 '어라...? 같은 물체인가?' 하는 상황이 벌어지게 된다.
만약 한 그릇에 이름이 같은 오브젝트가 동시에 있다면, 후디니는 이것을 올바르게 구분하지 못하는 상황이 나타날 수도 있다. 아니면, 동일한 물리규칙을 따라야 한다 라고 생각할 수도 있다.
만약 dop network 안에 총알이 100개가 있다고 했을 때, 이 100개의 총알의 이름이 모두 "bullet"으로 같다면, 올바른 시뮬레이션 결과를 얻지 못할수도 있다.
그래서 기왕이면(이라고 하지만 꼭) @name은 물체마다 다르게 설정해주는 것이 좋다. 이 부분은 constraint에서도 마찬가지이다.
그렇다면, 애초에 dop network 밖에서 서로 다른 이름으로 100개의 총알을 준비하면 되는것이 아닌가? 라고 생각할 수 있다. 물론 그렇게 해도 된다. 하지만 좀 더 있어보이는 방식으로 하면...
@name이 만들어져서 각 물체들의 구분이 가능한 상태가 되는 것은 SOP Network를 사용해서 Sourcing할 때 작업을 해주기로 한다. sourcing 전까지는 @prep_name / @ori_name 등과 같은 임시 이름을 사용해서 sourcing 할 때까지 가기로 한다. 그래야 나중에 치환과정에서 작업이 쉬워진다.




dop network 밖에서의 세팅은 이렇게 끝내기로 한다.
더 필요한 세팅이 있다면 시뮬레이션을 진행하면서 추가해줘도 충분하다.
기본적인 시뮬레이션 세팅을 잡도록 한다.

SOP network 안에 proxy 버전 총알을 불러온다.

이제 언제 / 어디에서 / 어떻게 불러와지고 어디에 합류될지 세팅을 해줘야한다.
일단 총알이 24프레임에 한번 등장한다고 가정하고 세팅을 잡아주자.


언제 / 어디에서 / 어떻게 중 '언제' 를 해결했다.
이제 '어디에서' 로드될 것인지를 세팅해주자.(생성 위치)



'어디에서' 도 세팅되었다.
이번에는 '어떻게' 등장하느냐 이다. 이 때의 '어떻게' 에는 생성될 때의 초기 속도, 회전 속도(회전력) 등을 생각할 수 있을 것이다.
랜덤한 v와 w를 만들어주기로 하자.
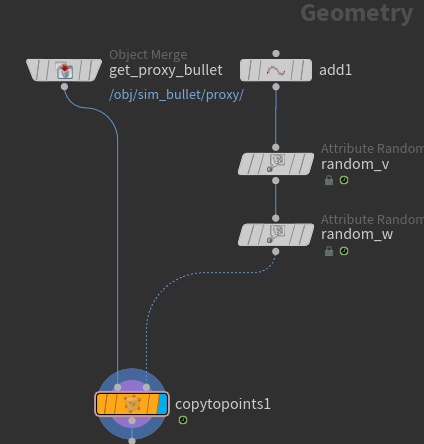

현재 spreadsheet를 보면, 가장 중요한 @name이 없다.
dop network에서 만들어줬던 @prep_name은 dop network가 공식적으로 이름으로 인정해주는 어트리뷰트가 아니다. 구체적으로 @name이 있어야 dop network가 이해하기에 구분이 가능한 이름이 되는 것이다.
- 마치 우리가 @vel을 가지고 있다고 해서 아무런 과정 없이 @v로 사용되고 그런것은 아닌것과 같은 이치이다.
이제 @name이 필요하다.
- 현재는 총알이 하나밖에 없어서 큰 문제가 발생하지 않을 수 있지만, 만약 2프레임마다 총알이 계속 나온다고 하면, 각각 고유한 이름을 가지고 있어야 dop network가 올바르게 각기 다른 오브젝트로 인식하고 시뮬레이션 작업을 진행할 수 있다.




24프레임에 총알 하나가 잘 나와서 시뮬레이션이 작동하는 것을 확인했다.
이제 10프레임에 한번씩 총알이 나오도록 세팅해보자.

switch의 판별식을 바꿔줘서 10프레임마다 한번씩 총알이 solver에 합류되도록 해줬다.
RBD Packed Object의 geometry spreadsheet를 확인해보자.

이제 hard 버전으로 치환해보자.
시뮬레이션 데이터를 가져올 수 있는 두가지 방법이 있다.
- Dop import 노드를 활용한 방법
- Object Merge를 활용한 방법


이렇게 연결해준다고 해서 제대로 된 결과가 나오진 않는다.


치환은 이뤄졌지만, 총알 하나만 치환되었다.
하나만 바뀐 이유가 무엇일까?
어떻게 하면 여러개의 총알에 대해서 모두 hard 버전으로 치환해줄 수 있을까?
문제 안에 답이 다 있다.
'여러 총알에 대해 hard 버전과 치환을 해주면 된다.'
- for - each 노드를 사용하면 된다.

한가지, hard 버전은 현재 @name이 따로 없다. 그렇기 때문에 transform pieces 노드의 치환 조건인 attribute를 name에서 prep_name으로 바꿔주도록 한다.(작동은 되지만, 안정성을 위해서 바꿔주도록 한다.)




총알 시뮬레이션 끝.
복합 시뮬레이션 - 레고 (난이도 : 중)
lego를 시뮬레이션 해보자.
일단 lego에서 어떤 단계를 불러올 것인지를 정해줘야한다.
생각해줘야할 것은, 마지막 순간에 proxy 데이터를 고화질 데이터와 치환해주기 좋도록 자료를 준비해주겠다 라는 것이다.
시뮬레이션의 최종결과로 사용되는 @name은 단 하나도 같아서는 안된다. 이것을 미리 염두에 두고 작업을 진행해야한다.
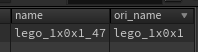
일단, 시뮬레이션에 들어가기 전, 이름으로 사용할 @ori_name의 규칙을 정해보도록 하자.
우리가 사용하려고 하는 @ori_name의 형태는 "lego_NxM"이다.
- 여기에서 N은 x의 정보, M은 z의 정보이다.
현재 레고 블럭의 크기가 너무 크다.

크기를 줄여야할 필요가 있다.

tip)
사이즈 조절을 할 경우, packing을 한 뒤 사이즈를 조절하는것 보다는, 사이즈를 먼저 조절해주고 packing 해주는 것이 작업에 더 안전하다.
그래야지 transform pieces에서 올바르게 인지할 확률이 높아진다.


아까 총알과의 다른 점은, 데이터의 수량이 좀 되기 때문에 object merge로 불러와준 proxy 데이터와 변환할 hard 데이터를 file cache로 저장해주는 것이다.


지금까지의 핵심은 @name을 바로 만들어주는 것이 아니고, 이전에 더 근본적으로 사용되는 이름이 있다는 것이다.
sourcing 준비를 해보자.


일단 기본적인 sourcing 세팅을 잡았다.
이제 디테일하게 세팅을 잡아보자.
이번에 중요한 것은, 준비된 오브젝트가 하나가 아니라는 것이다.
어떠한 오브젝트를 골라서 사용할지 이 부분을 작업해줘야한다.
일단 sort > random 으로 레고를 섞어주자.


매 프레임마다 순서가 섞이길 원한다면, sort의 parameter 중 seed에 $FF를 기입해줄 수 있을 것이다.

그리고 이렇게 섞이는 레고 안에서 blast로 하나만 떼어내준다.

이제 이름은 무엇이고 언제, 어디에서, 어떻게 로드될 것인지(시뮬레이션에 필요한 정보)를 세팅해줘야한다.

원운동을 하는 포인트를 만들어주고, 그 포인트의 위치를 기반으로 lego 블럭이 로드되도록 해주자.

이제 랜덤한 초기 속도(v)와 초기 회전속도(w)를 세팅하자.

블럭이 합류되어 로드되는 타이밍(언제?)은 switch 판별문으로 정해준다.
- 2 프레임마다 레고 블럭이 로드되도록 했다.


약간의 디테일을 수정해줬다.
- 블럭이 로드될 때 위쪽으로 살짝 튀어오르고 나서 떨어질 수 있도록 초기 v 값을 설정해줬다.

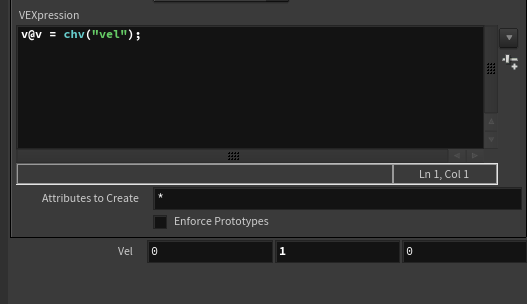


만약 한프레임에 여러개가 로드되도록 하려면 어떻게 해줘야할까?
고려해줘야할 것은, 같은 프레임에 여러개의 블럭이 생성되게 되면서 @name이 같은 블럭이 나오게 될 확률이 생겼다는 점이다.
@name 생성규칙을 좀 손봐야할 필요가 있다.

위 이미지의 세팅을 여러개 복사해서 merge로 묶어주는 방법이 있다.
하지만 몇십개의 블럭이 한프레임에 나온다고 한다면, 위의 세팅을 몇십개 복사해서 연결해주고 하는 것은 매우 비효율적으로 보인다.
세팅을 대대적으로 손봐주기로 한다.

@count 어트리뷰트를 만들어줬다. 이 어트리뷰트는 한 프레임에 '몇개'의 블럭을 로드할 것인지 정해주는 어트리뷰트이다.


그리고 @name을 수정해준다.


각 프레임마다 생성되는 블럭의 @ptnum을 붙여줌으로써 N 프레임에 생성된 M번째 블럭 뉘앙스의 이름이 붙게 된다.
이렇게 생성된 블럭을 copy to points로 원운동하는 점에 붙여주면, 결과가 매우 참담하다.

모두 같은 위치에 같은 seed를 가진 v와 w를 갖게 되면서 겹쳐지게 된다.
어떻게 하면 이 블럭들을 흩어줄 수 있을까?
각각의 블럭들에 대해서 copy to points를 실행해주면 된다.
- for each primitive 노드를 사용한다.
- 서로 다른 seed를 가지도록 하기 위해서 metadata를 활용해서 seed에 더해줌으로써 각각의 블럭이 다른 seed를 가지도록 해준다.
- 같은 위치에서 생성되기 때문에 씹히는 일이 발생한다. attribute randomize 노드를 사용해서 약간의 포지션 정보를 초기 포지션(원운동하는 포인트의 위치정보)에 더해준다.


이제 고화질 데이터로 치환해보자.




proxy 블럭과 @ori_name이 일치하는 블럭으로 치환해줘야했기 때문에, 고화질 데이터 목록에서 현재 치환하기 원하는 Proxy 데이터와 @ori_name이 같은 블럭을 제외하고 날려주는 작업을 중간에 넣어줬다.
레고 시뮬레이션 끝.
레고 시뮬레이션 작업을 진행하면서 중요한 이야기가 많이 나왔다.
Sourcing에서 기본적으로 몇 프레임 단위로 로드하는가? 라는 개념에서 좀 더 능동적으로 조절해줄 수 있는 방식으로 디벨롭 되었다.
심지어는 한 프레임에 몇개의 오브젝트가 등장할 것인지도 정해줄 수 있었다.
그리고 새로운 점으로는 여러 방식으로 피스들을 준비하고 활용하는 것이 가능해졌다는 점이다.
복합 시뮬레이션 - 나무조각 (난이도 : 상)
나무 조각을 가지고 시뮬레이션을 진행해보자.
이번에 우리가 주의할 것은, 준비된 자료의 상황에 따라서 필요한 세팅이 조금씩 다르다는 것이다.
우리가 나중에 원하는 작업을 할 때도 마찬가지이다.
상황에 따라서 세팅을 유연하게 변경할 수 있어야한다.
plank를 확인해보면 현재 오브젝트들이 확인하기 편하도록 주욱 늘어서있다.

시뮬레이션 작업시 필요없으니, 한점으로 모아주자.
그리고, packing 과정에서 origin(원점)을 기준으로 pivot을 설정해주는 것 또한 중요하다.
- pack에서 위의 pivot 말고도 신경써야할 부분이 있다.
올바르게 준비된 이름을 설정해줘야한다.
이름부터 설정해주자.
이름을 잘 짓는 이유 : 마지막 단계에서 치환을 잘 해주기 위해서
proxy와 high 데이터를 어디에서 불러올지 확인을 해준다.


그리고, 위에서 언급한대로, packing은 사이즈를 조절한 뒤 하는 것이 안정적이다.
하지만 현재의 세팅은 packing된 박스의 사이즈를 조절해주고 있다.
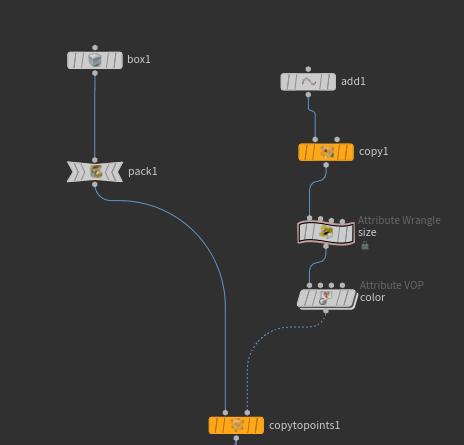
정육면체의 box를 packing해주고, size를 조절해서 직육면체로 바꿔줬다는 것이 나중에 문제를 일으킬 수 있는 부분이다.
Proxy로 사용하려는 오브젝트는 최초로 packing된 상태이어야한다.
- proxy와 packing 사이에 어떠한 변형이 있어서는 안된다.
packing된 오브젝트에 어떠한 변형을 가하고 그 데이터를 Proxy로 사용하면, 올바르게 치환이 안될 수 있다.
예를 들어 나무조각의 치환이 이뤄질 때, hard 데이터는 최초로 packing이 이뤄진 오브젝트와 비교를 진행하는데, 이 때 packing 이후에 변형된 물체를 proxy로 사용하고 있었다면, hard 데이터는 직육면체 모양의 proxy 데이터가 아닌, 최초로 packing이 이뤄졌던 정육면체 box와 비교를 진행하게 되면서 올바른 치환이 이뤄지지 않는다.


현재의 세팅의 문제점은 위에서 언급한것처럼, packing 이후에 size의 변형이 일어나고 있다는 것이다.
해결방안은 크게 두가지가 있다.
쉬운 방법)

한가지는 각각의 size가 변형된 box에 대해 unpack으로 압축을 풀어주고 다시 packing을 진행하는 것이다. 이렇게 되면 proxy로 사용하려 하는 packing된 box의 size 변형 시점은 packing 이전이 되므로 문제가 발생하지 않는다.
이렇게 세팅을 진행하는 경우, color 노드 아래에 @ori_name에 대해 정의해주고 attribute copy를 활용하여 정보를 넘겨준 뒤 Proxy로 사용하면 될 것이다.
쉽지 않은 방법) (훈련을 위해서 이 방법을 사용하기로~)
또 한가지 방법은 packing이 발생하는 시점을 뒤로 밀어주는 것이다.
- 문제의 핵심은 packing 이후에 size의 변형이 일어났다는 것이다.


하지만 box에 미리 packing을 진행하면

packing을 미리 했을 때와 하지 않았을 때의 결과는 분명 다르다.
하지만, 우리가 초기에 생성했던(가지고 있던) 정육면체의 box는 copy to points에 의해 모양이 바뀌었다.

assemble 노드를 활용해서 이어져있는 primitive를 같은 이름으로 묶어준다.
- 이어져있는 조각을 각각 구분지어준다.
- 위의 내용에 assemble 노드를 달아주면, 각각의 박스가 조각별로 구분이 된다.
- 이 때 구분을 위해서 Output Prefix 에 기입된 정보가 남게 된다.
- 같은 이름으로 분류되는 조각들은 하나로 묶어서 하나의 조각으로 인식한다.(조각덩어리 느낌?)



위의 이미지를 보면 primitive 0~5번의 경우 이어져있기 때문에(하나의 box) 같은 name을 부여받았고, 이것은 하나의 조각으로 인식하게 된다.
여기에 Create Packed Geometry(19버전은 Create Packed Primitives)를 활성화해주면, 같은 name을 가진 primitive(이어져있다고 판단되는 primitive)가 하나의 조각으로 packing된다.


@name은 오브젝트를 dop network의 그릇안에 올렸을 때 사용할 어트리뷰트이기 때문에, 다른 어트리뷰트를 사용해서 이름을 만들어줄 필요가 있다.(ex. @ori_name, @prep_name)



색에 대해서는 나중에 color palatte를 사용해서 임의의 색을 넣어주기로 할 계획이기 때문에 bypass로 color 노드를 비활성화해준다.

굳이 이와같이 나무조각을 나열해놓을 필요가 없다.
또한 packing된 나무조각의 pivot이 원점에 가있도록 세팅을 수정해주자.

pivot의 위치에 대해서는 assemble 노드에서 packing이 일어날 때 pivot location이 origin(원점)으로 올 수 있도록 해준다.

high 버전의 pivot 위치도 확인할 필요가 있다.

일단 위치는 {0, 0, 0}에 놓여있다.
high 로 사용될 데이터가 마지막으로 packing된 위치로 가보도록 하자.

pack 노드를 눌러주면, 포인트의 위치가 원점이 아닌 것을 확인할 수 있다.

하지만 최종 hight 데이터의 위치는 원점에 놓여져있다. 왜 그럴까?

이곳의 세팅 과정에서 스케일 조절을 통해서 바운딩박스에 packing 데이터를 맞췄기 때문이다.
- 이 부분은 수정이 필요하다.
high 데이터에서도 확인해줘야할 부분이 있다.
Proxy로 제공하고 있는 box들은 현재 pivot의 위치가 origin(원점)이다.

이 proxy 데이터를 받아서 만들어진 high 데이터의 pivot도 확인해보자.

이런 오차로 인하여 transform pieces 노드가 올바르게 작동하지 않을수도 있다.(올바른 치환이 이뤄지지 않을 수 있다는 뜻)
이 두가지 문제점을 수정해보자.
1) 최종 packing 데이터의 pivot 위치
- pack parameter 중 Pivot Location을 Centroid에서 Origin(원점)으로 설정해준다.

high 데이터의 pivot 위치도 다시 확인해보자.

놀랍게도 high 데이터의 pivot 위치도 원점이 되었다.
첫번째 문제 해결에서 두번째도 해결되었다.
packing된 데이터의 스케일을 맞춰주기 위한 작업이 packing 이후에 진행되기 때문에, 이 부분을 잡아주기 위해서, 마지막에 unpack으로 압축을 풀었다가 다시 packing을 진행해준다.

- 이 때도 pack 노드의 pivot location은 Origin이다.
- 다시 packing을 해주면서 우리가 가지고 있던 @ori_name, @prep_name의 정보가 사라져있다.
- attribute copy로 두 어트리뷰트를 가지고 온다.



이렇게 high와 proxy의 정보가 동일해졌다.
시뮬레이션 세팅을 잡아보자.
일단 proxy 데이터와 high 데이터를 불러와서 cache로 뽑아준다.

dop network를 불러서 기본 세팅을 진행한다.


10프레임마다 나무조각이 하나씩 로드되도록 판별식을 작성해줬다.

시뮬레이션이 잘 작동하고 있다
이제 proxy 데이터를 high 데이터로 치환해주자.

우리가 불러오게 될 high 데이터는 나무조각'들' 이다. '각각의 proxy 데이터'에 대해 (우리가 지정해주는) 이름 attribute를 대조해서 서로 같은 오브젝트로 치환하고, 이름이 다른 조각들은 날려버리도록 attribute wrangle을 세팅해준다.





잘 치환되는 것을 확인할 수 있다.

나무조각(plank) 시뮬레이션 끝.
이렇게 기초적인 Rigid body 시뮬레이션이 끝났다.
다음부터는 constraint에 대해서 공부한다고 한다.
선생님이 보여주신 예제를 보니까 이것도 또 두근두근하게 만드는 그런것이 있다.
지난시간에 만들어보았던 procedural modeling이 참 많이 와닿는다.
예전에 한번 megascan 데이터를 가져와서 기본적인 건물을 procedural 하게 만들어보려고 시도'만' 했던 기억이 있는데, 이제는 (좀, 아니 아주 많이 고민해봐야겠지만) 규칙을 정해주고 그 규칙을 따르는 procedural modeling을 도전해볼 수 있을 듯 싶다.
정말 새삼, 강의를 듣기 잘했다는 생각이 드는 밤이다.



